
Psst… 🔎 Looking for GopherCon, 2021, TR resources? Say no more:
- GopherCon TR, Dec, 2021: Friends Don’t Let Friends Hard-Code Their Secrets
- ✴️ Slides
- ✴️ Source Code
Here is a video recording of the demo we made too:
mTLS Using Spire Under Three Minutes
Make sure you watch the longer video below, and read the rest of the article too.
Enjoy, and may the source be with you 🦄.
⚠️ Important ⚠️
If you are new to SPIFFE and SPIRE, read the rest of the article first before watching the video.
Lecture
Setting Up SPIRE on EKS in Less Than Ten Minutes
Introduction
This article will look at what SPIFFE and SPIRE are. Then, we’ll explore why managing identities and Trust at scale is a tough challenge and how to solve it in a repeatable, scalable, and platform-agnostic way.
![]()
SPIFFE and SPIRE Logos
In the video that accompanies this article, you’ll see how you can configure SPIRE on an AWS EKS Kubernetes cluster. Then we’ll ensure that it can fetch SPIFFE ID documents (or SVIDs) from the SPIRE Server.
SVIDs, which stand for SPIFFE verifiable identity document, are specially-crafted X.509 Certificates that the Workloads can use to authenticate with each other.
**SVIDs Rotate Automatically
SVID**s are short-lived, their lifetime is 1 hour by default, and they are renewed every 30 minutes so that you don’t run out of SVIDs due to TTL.
But before going any further, it’s better to clarify all this buzzword bingo—I mean, what is a “workload”?—what the heck is and SVID? Why do we even need it? Can we eat it 😁?
What is a Workload?
Let’s start with something familiar: The workload.
A workload, in the context of SPIFFE and SPIRE, is anything that does a computation.
Portable and Platform-Agnostic
In Cloud-Native terms, a workload is an integrated stack of application, middleware, and operating system that accomplishes a computing task. A workload is portable and platform-agnostic. A workload, or a collection of workloads makes up a business service.
Let us take the project that we have been developing so far, for example. In that case, the idm, crypto, mailer, questions, and store pods that expose RESTful APIs in our Kubernetes cluster are all workloads.
➜ ~ kubectl get po
NAME READY STATUS RESTARTS AGE
client-649db6b744-g85wb 1/1 Running 0 23d
crypto-66d75ccdbf-k2khl 1/1 Running 0 31d
idm-b9497f654-r7qg6 1/1 Running 0 31d
mailer-6d5c745b87-nz9dt 1/1 Running 0 31d
questions-67d5559dd9-dglc6 1/1 Running 0 31d
store-74bd85799b-w5xx9 1/1 Running 0 31dPods in our FizzBuzz Pro production cluster.
Workloads will often need to communicate; they must send API requests to different downstream workloads and receive API responses.
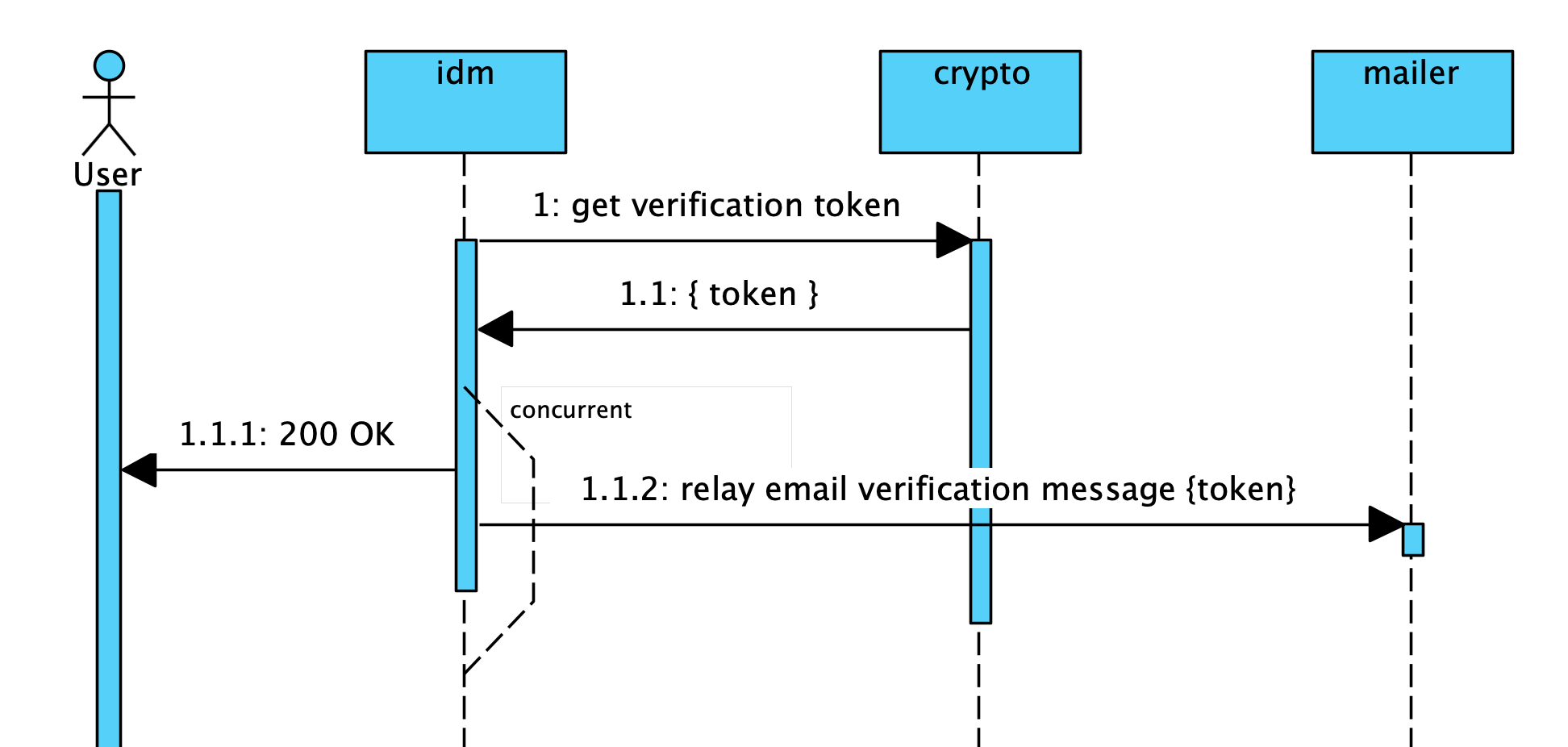
FizzBuzz Pro email verification flow.
In the above sequence diagram, the idm workload talks to the crypto workload to get a verification token. Then, the idm workload talks to the * mailer* workload to relay that token in an email message.
Workload == Service
One more thing before I move further: In this article, and also in the video that accompanies this article, I use the terms workloads and services interchangeably. Our microservices are our workloads, don’t get confused.
Within the context of this article, a workload or service is a process that lives on a physical or virtual machine and does some form of meaningful computation. Workloads often communicate and exchange information through protocols like RESTful APIs, protocol buffers, domain sockets, or other inter-process communication mechanisms.
“Hope” Is Not a Security Posture
The problem is, how do we secure this communication channel between the workloads that we have?
One way to take care of this is to create a large enough trust boundary to know that the network is trusted. Then you hope no malicious parties can get inside this secured zone to attack your services.
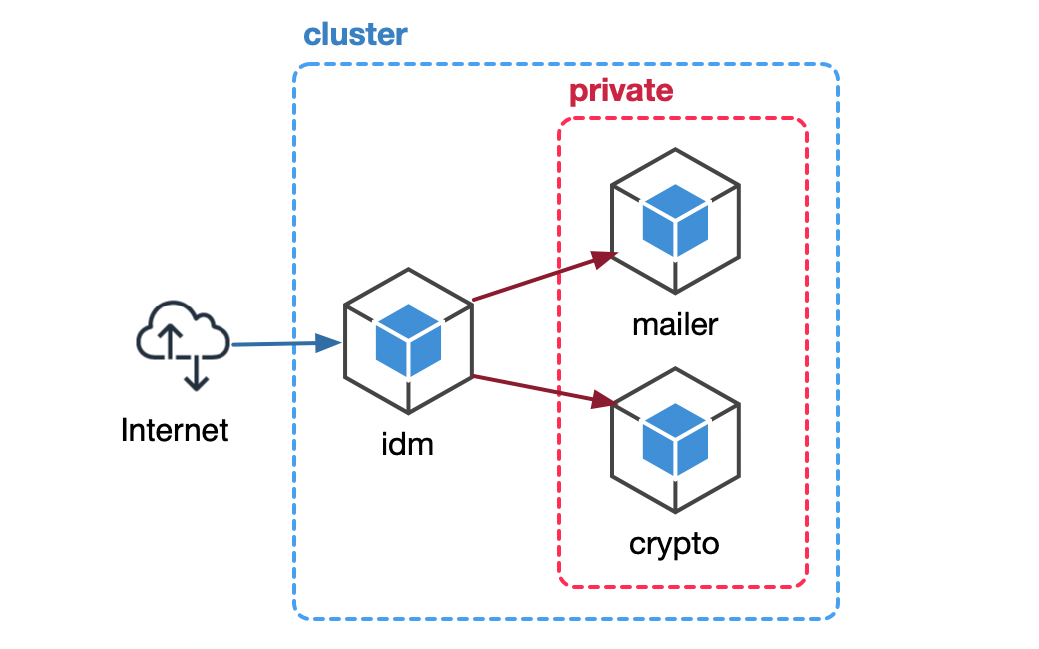
A subset of FizzBuzz Pro microservices' network boundaries.
If we look into the above network boundary diagram, the mailer and **crypto ** services are inside a private network; they don’t expose any public APIs. We hope this could be enough to secure them.
Hope is not the best strategy in terms of hardening your security posture. I won’t dive into too much detail in this article, and there are so many ways * hope* as a security strategy can go wrong.
To give a single example, though, assume we have another pod here (see the diagram below). This pod is a web-ui pod that has nothing to do with mailer and crypto. Therefore, it should not know about these services and not care that they exist at all.
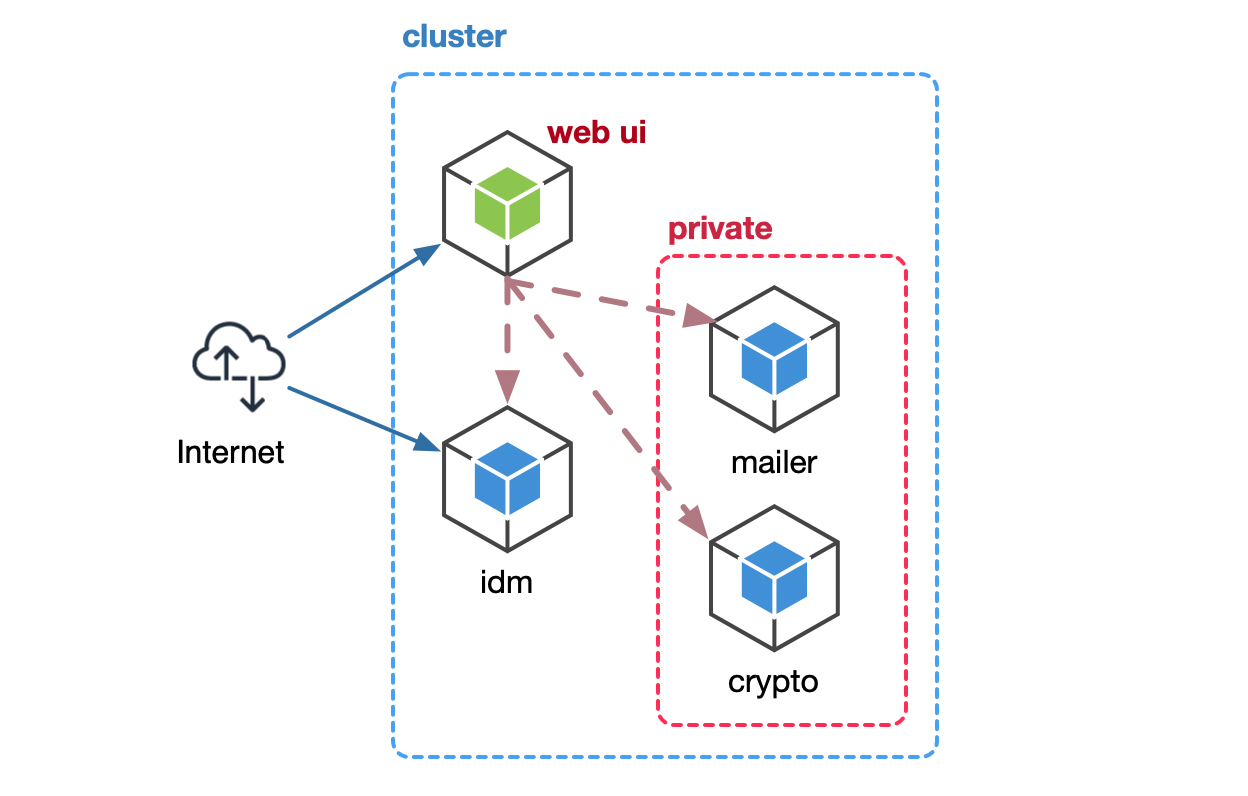
A brand new web UI pod, reaching larger parts of the network than it should.
Can you hope that this service will not start talking to the crypto service, generate random tokens? Can you ensure there isn’t a vulnerability in a dependency that it uses? How about a dependency of a dependency of a dependency… 🐢? Can you be sure that the code is free of logic errors? Can you be sure that the pod will not start acting weirdly all of a sudden?

This is why code reviews are a good thing.
Can you hope that nothing like this could happen?
Hope is not a strategy. Instead, it would be best if you hardened the communication between these workloads. That way, only the intended parties could talk to each other. No one else in the network could manipulate this communication.
Zero Trust
That’s where the concept of Zero Trust comes into play. Again, you can learn more about it in the References and Further Reading section at the end of this article, but in essence, Zero Trust means that you cannot trust the network. Therefore, you should assume that your network is insecure and is breached by default.
Zero Trust is a network security model based on a strict identity verification process. The Zero Trust Security Model dictates that only authenticated and authorized workloads can talk to other authenticated and authorized workloads.
Here are some of the key motivations behind the Zero Trust Security Model:
- Users, devices, applications, and data are moving outside trust boundaries all the time. Now it’s near impossible to do perimeter-based protection.
- “Trust but verify” is no longer an option, as targeted, advanced threats constantly move inside the corporate perimeter.
- The network has become a complex mess with the introduction of cloud apps and the Internet of Things. The increased risk is not compatible with traditional access-control-list-oriented network security models.
The CIA Triad 🕴
Then, the question reduces to “how do we ensure workload-to-workload communication where the network is untrustworthy?”.
So how do we secure service-to-service communication then?
This puzzle has three parts to solve, also known as the CIA Triad: * Confidentiality*, Authenticity, and Integrity.
Confidentiality: The workload-to-workload communication should be on a secure channel that no one else can listen to.
Integrity: The message that is being sent from one workload has not been tampered with. The data is complete, accurate, and hasn’t been altered by anyone else.
Authenticity: The sender of the data is the workload who claims it is. It is not some other service that’s trying to impersonate the original service.

The CIA triad.
X.509 Digital Certificates
There are well-established, industry-standard ways of solving the puzzle. We can establish confidentiality, verify integrity, and ensure authenticity in an industry-standard way.
The most common way is to use asymmetric cryptography and X.509 Digital Certificates. Again, I’m not going into too much detail about certificates and certificate chains. Check out the reference material at the end of this article for a deeper drill-down on the subject matter.
For the context of this article, we need to know that when two workloads have each other’s X.509 public keys, they can establish a secure communication channel. Then, they can talk to each other through this secure communication channel.
Moreover, they can prove the message’s authenticity and integrity by digitally signing the message with their private key.
Finally, they can ensure the confidentiality of the communication channel by encrypting the payload with the receiver’s public key.
How these mechanisms work varies by the algorithm and implementation, and it’s a bit more involved than the quick summary outlined above. Suppose we sacrifice a little bit of rigor for clarity. In that case, we can say that when you have your Certificates of Trust, you can ensure confidentiality, integrity, and authenticity in your workload-to-workload communications.
Meet SPIFFE
The following outstanding question is: “Since they are so helpful, how do we create these X.509 Certificates?”
Other questions one might wonder are:
- Since these certificates ensure secure service-to-service communication, it’s a good idea to rotate them frequently. How do we do that?
- And also, it’s a good idea to invalidate them if some of these certificates leak. How can we do it?
- Also, how do we optimize and automate the process the certificate rotation and expiration?
Why automate? Because security and humans do not mix well together. So we better automate this entire certificate generation, rotation, revocation, and invalidation process without needing any human intervention.
That’s where SPIFFE comes into play.
SPIFFE, the Secure Production Identity Framework For Everyone, provides a secure identity, in the form of a specially crafted x.509 certificate, to every workload in your production environment.
Short-Lived Keys
The heart of the SPIFFE specifications is the one that defines short-lived cryptographic identity documents – called SVIDs via a simple API. Workloads can then use these identity documents when authenticating to other workloads.
SPIFFE is a set of open-source specifications for a framework capable of bootstrapping and issuing identity to services anywhere without depending on any specific platform.
There Are JWT SVIDs, Too
There are other ways SPIFFE provides identity documents too, but in this article, we’ll talk about X.509 identities only. More specifically, X.509 SPIFFE Verifiable Identity documents or SVIDs.
SPIFFE Key Elements
SPIFFE has the following key components:
- The SPIFFE ID, how a software service’s name (or identity) is represented.
- The SPIFFE Verifiable Identity Document (SVID), a cryptographically verifiable document used to prove a service’s identity to a peer.
- The SPIFFE Workload API, a simple node-local API that services use to obtain their identities without the need for authentication.
- The SPIFFE Trust Bundle, a format for representing the collection of public keys in use by a given SPIFFE issuing authority.
- SPIFFE Federation, a simple mechanism by which SPIFFE Trust Bundles can be shared.
Benefits of Using SPIFFE
By using SPIFFE, you won’t need to maintain application-level authentication information.
No Tokens, No Problem
Think about it. That’s something BIG:
You won’t need a unique secret service key or a special token for your workload to prove its identity anymore.
In addition, SPIFFE is a platform-agnostic standard, so you avoid vendor lock-in by using it across your clusters.
And since SPIFFE is an open standard, you can interact with any application or service that supports SPIFFE without having to modify your codebase or your application configuration.
Moreover, SPIFFE solves the automating the credential creation problem that we mentioned before. It is an open standard that establishes how these SVID x.509 Certificates are created, defined, rotated, verified, and invalidated automatically without needing human intervention.
Caching and Performance
The workloads periodically receive updated identity documents (i.e., SVID s) as certificates expire or the configuration changes. The SPIRE agent * preloads* the identities for all workloads it may host. This preload operation minimizes the impact of server downtime on the availability of the Workload API.
In addition to all these, you won’t have to assume that your network is secure because the SVIDs will ensure the security and integrity of service-to-service communication that the services have.
That’s a great advantage because maintaining network access control list and firewall rules is cumbersome. It is prone to human errors, time-consuming, and impractical when your network boundaries and the network overlays you use change all the time.
Hello, SPIRE
Okay, that was SPIFFE. But, what is SPIRE?
{{img( src=“/images/2021/10/keymaker.png”, alt=“SPIFFE defines how to make keys; SPIRE is the key maker.” )}
About SPIRE
If SPIFFE is a set of standards, what implements those standards? That’s where SPIRE comes into play.
SPIRE is a production-ready reference implementation of SPIFFE.
SPIRE does its job by performing node and workload attestation. This way, it reliably and securely identifies workloads and issues them SVID s (SPIFFE Verfifiables IDs), which are nothing but specialized X.509 Certificates. The workloads, then, can use them to prove their identity.
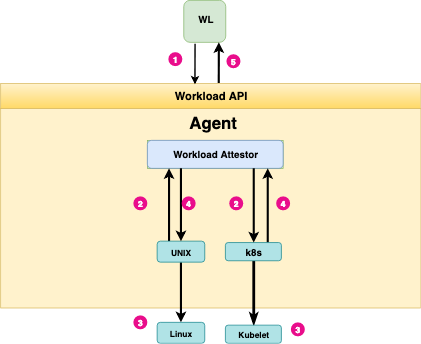
Workload attestation.
You’ll see an example of how this attestation flow works in the video I’ve added to the beginning of this article.
If you want a quick summary, workload attestation is a process where the SPIRE agent relies on locally trusted workload attributes. These attributes can be as process/group ID or container runtime metadata. Some examples of these metadata include the pod names, namespaces, service accounts, and the like.
After all, if our cluster’s Kubernetes API can attest that our workload pod has a particular name, with certain tags, managed by a specific * service account*, in a given namespace, in a known cluster… that is enough information to identify this workload.
This way, the workload will not need to provide a secret key to prove its authenticity. Instead, we shift the trust and responsibility of establishing the workload’s authenticity to the orchestration framework (Kubernetes in this case). By talking to Kubernetes APIs, we can verify, with confidence, that this workload pod is what it claims it is.
Node and Workload Registration
One thing that I’ve been conveniently hiding so far, is, you have to * register* nodes and workloads before you can attest them. For the interested, this document outlines the details of how workloads are registered with SPIFFE IDs in the SPIRE server.
🕵️♀️ SPIRE Agents
There is a single SPIRE Agent on each Node. The agents talk to the SPIRE Server. Multiple workloads on the node talk to the same agent using the SPIFFE Workload API to receive their SVIDs.
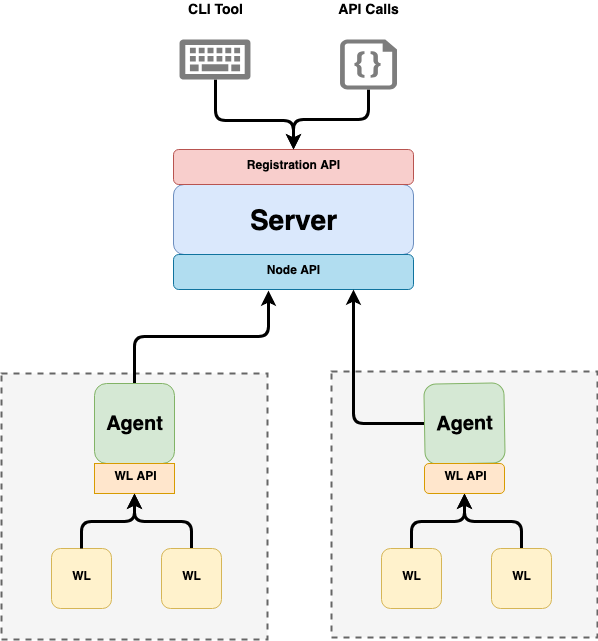
SPIRE Server and Agent architecture.
Registering a Workload
For workloads to receive SVIDs, they need to be registered first.
There are several ways to register a workload: Either an operator registers your workloads to the SPIRE server, and then the operator manually provisions the workloads. Or you can automate this step entirely in your CI Pipeline: Your CI/CD orchestration tool can register the workloads to the SPIRE Server and deploy them to your cluster.
You Define Your Attestors During Registration
The Workload Registration step is also where you specify your workload attestors to the SPIRE server. Then the SPIRE Agent will use those attestors to assign an identity to your workload and assign them SVIDs.
After the workoad registration is complete, workloads will bind to the spire agent’s domain socket and regularly fetch SVIDs.
And that’s all about it. After a successful registration, SPIRE takes care of the certificate initialization, assignment, revocation, and rotation problems when everything is set up, each of which is hard to solve individually.
go-spiffe
go-spiffe is a library that can make the “fetching SVIDs from the SPIRE Agent” part much painless (among other abstractions).
🐢 Secret Zero
What makes SPIFFE stand out is that it solves what’s called the “secret zero” problem. In a nutshell, the problem statement goes as follows:
- Enabling access control to service requires a secret such as an API key or password.
- That key or password needs to be protected, so you encrypt the key.
- But then you have to watch the decryption key that you’ll use to get your service key back.
- So you put the decryption key to a Keystore.
- But then you’ll have to protect the Keystore’s master key.
And this goes on and on. Ultimately, protecting access to one secret results in a new secret you need to save.
Which begs the following question: “Who protects the secret zero—the ultimate secret—that gives the keys to the entire kingdom?”.
Rest assured, we’ll get there. Just 🐻 with me for a while.
🐢 It’s Secrets all the Way Down
Identity and Authentication go hand-in-hand. Claiming an identity is useless unless you can authenticate that identity and prove with confidence that the identity is indeed what it claims to be.

Turtles all the way down.
One way to authenticate an identity is to provide a secret key or a password along with the identity. Then a second independent identity management service can verify this identity. In certain other implementations, services can use hard-coded secret service keys to identify themselves.
In either case, to prove the identity, you need a secret. But this secret is vital because if an attacker gets a hold of this secret, they can authenticate as the service holding the secret.
Do Not Hard-Code Your Secrets
That’s why hard-coding the secret inside the source code or baking it on a virtual machine image such as an AWS AMI is not a good idea.
Also, although the Twelve Factor App Methodology encourages it, storing secrets in the workload as environment variables can cause security problems (especially, in form of leaked environment variables inside the aggregated log streams)—Apps should ideally keep their secrets in temporary memory-mounted volumes.
A better way is to put the secret into a Keystore, let the service authenticate with the secret store, and let the service get it from the key store.
A third-party orchestration system can authenticate with the Keystore by unlocking the Keystore using the Keystore’s master key. Then it can fetch the secret key that the service will use. Then inject it as a read-only, in-memory configuration volume to the service and then lock the Keystore so that no one else can reach it.
But then, how do we protect the Keystore’s master key? Because if an evil attacker gets it from our orchestration system somehow, then we are at square zero; they will get all the keys to all the services.
HashiCorp Vault, for example, attempts to solve this problem using Shamir’s Secret Sharing Algorithm.
Vault splits the key into three or more parts; if you don’t provide either all the parts or the majority of the parts (depending on how you set up Vault), Vault will not unlock.
So it makes getting the key harder, but still, it’s just pushing the problem one level down, not entirely solving it.
No matter how hard it is, if you get the three master keys from wherever they are stored, you can generate what Vault calls the “unseal key.” Then, you gain access to the entire kingdom again.
To add more security, you can use Vault’s “auto unseal” feature and delegate the providing and rotating of the unseal key to a bare metal or *cloud_ HSM. But now, you’ll need to protect the HSM’s master key because reaching it will give access to Vault’s unseal key, which will provide access to all of your service secret keys.
🐢 Solving the Bottom Turtle
Do you see the issue here?
Managing secrets at scale requires effective access control; implementing access control requires validating identity. That’s because without providing a valid identity, it will be “public access,” which defeats the entire purpose of using secret keys in the first place. Yet, proving identity requires possession of yet another secret—That’s akin to stacking one turtle atop another. It’s turtles all the way down 🐢.

A turtle in the bottom of the ocean (a 'bottom turtle'?).
🐢 Turtles All the Way Down
“Turtles all the way down” is an expression of the problem of infinite recursion. The saying alludes to the mythological idea of a World Turtle that supports a flat earth on its back. It suggests that this turtle rests on the back of an even larger turtle, which itself is part of a column of increasingly large turtles that continues ad infinitum.
Protecting one secret requires coming up with some way to protect another secret, which then requires protecting that secret, and so on.
That’s why improperly designed secrets management solutions have a master key that unlocks everything. All a hacker needs to do is either steal or guess this one master password to access everything. This master password is secret zero.
This approach is equivalent to locking all of your keys in a drawer and then putting the key of the drawer under the flower pot in your backyard—don’t do that 🙃.
To break this loop, we need to find a bottom turtle, that is, some secret that provides access to the rest of the secrets we need for authentication and access control.
The next section is about how to find the bottom turtle.
The Shift of Trust
A better solution to secret zero is a tad counterintuitive:
What If I Told You…
Instead of securing the secret zero, what if we didn’t use any secret at all?
As it happens, we can avoid the secret zero problems entirely by leveraging authenticators that work with the underlying infrastructure to authenticate the access to your secrets.

No secrets, no problem.
In SPIRE, this authentication process is called attestation. You attest both the nodes and also the workloads.
**What are Nodes?
Nodes** are virtual or physical machines, and workloads are processes running on these nodes either directly or inside a container in a pod.
To verify that a workload is authorized for a particular identity, the SPIRE agent performs workload attestation. During workload attestation, workload’s attributes are read from the kernel or other trusted components on the local system. Then, the SPIRE agent matches the attributes against configured identities and provides each workload with all the identities for which it is authorized.
Two Workloads Can Share the Same ID
Note that workload-identity association is a many-to-many relationship: A workload may be authorized for zero or more identities. Similarly, zero or more workloads can be associated with a single identity.
For example, if the Kubernetes api-server can verify that your pod has a name idm, living inside a cluster named fizz-cluster using a service account named fizz-sa under a namespace fizz; that is adequate identifying information to prove the identity of the idm pod with confidence. So even if the pod does not provide any secret, the SPIRE workload attestor plugin can verify the identity of the idm pod by talking to Kubernetes APIs.
Root of Trust
During the workload attestation process (as exemplified above), SPIRE establishes a Root of Trust. It builds an automated solution around workload identity. This identity then forms the foundation for all the interactions that require authentication and authorization.
There’s No Spoon
In other words, when you use SPIRE, you shift the burden of trust from the Keystore to the operating system’s kernel, the cloud provider APIs, the orchestration framework, or to a mixture of all of these.
It’s a good time to re-intruduce the SPIRE workload attestation diagram. Pay attention to how the workload attestor uses different plugins to use * kubelet* for Kubernetes-native workloads, and the linux kernel for other workloads. This plugin-based architecture is one of the reasons why SPIRE is so easy to extend.
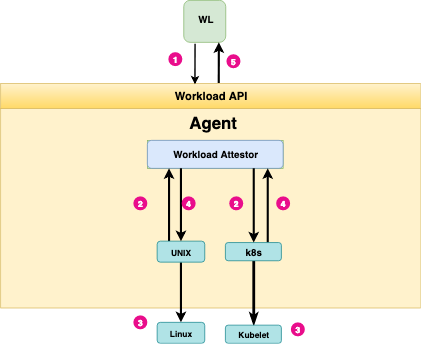
How the SPIRE workload attestation works is—at a very high/conceptual level—similar to how the AWS Instance Metadata API works or how the instance metadata API of any other cloud provider functions.
In a similar fashion to the AWS Instance Metadata API, the SPIRE Workload API does not require that a calling workload have any knowledge of its own identity or possess any authentication token when calling the API. Using the Instance Metadata API means your application does not need not co-deploy any authentication secrets with the workload:
There’s no spoon.

SPIRE workload attestation.
Unlike these other APIs, however, the SPIRE Workload API is platform-agnostic. In addition, it can identify running services at the process level and kernel level, making it suitable for use with container schedulers such as Kubernetes.
Having learned the basics of SPIFFE and SPIRE, let’s look at some use cases from companies that use SPIFFE on scale production.
Use Cases
Here are some examples of real-life use cases that talk about SPIFFE and SPIRE out in the wild.
- Using SPIRE in Production at Uber
- Overcoming the identity crisis at Pinterest with SPIFFE
- 10 Lessons From Migrating to SPIFFE After 10 Years Of Service Identity at Square
- Passport App: The role of SPIFFE and SPIRE in return to work solution
- SPIFFE at GitHub
- Securing Kafka with SPIFFE
- Attesting Istio Workload Identities with SPIRE
- Parsec and SPIFFE
- Cloud-Native Identity Management
- Using SPIFFE and SPIRE to ensure secure communications across hybrid infrastructure services
- Securing Grey Matter: SPIFFE/SPIRE in a Hybrid Mesh
- Building Zero Trust-based Authentication in Healthcare with SPIRE
- Lessons Learned: Designing Scalable, PKI-based Authentication With SPIRE at ByteDance/TikTok
Use The Source
Here’s the zip archive of the project that we’ve used in the demo video (32KB). There are other manifest files that are not part of the demo. Yet, I’m keeping them to give a more complete view of the system that we are working with.
Aside
In the source code archive, I have not included Kubernetes Secret manifests for obvious reasons—also, after reading this article, who needs secrets anyway.
¯\_(ツ)_/¯.
References and Further Reading
Here is some additional “bedtime reading” for those who want to dig into the concept further.
Kubernetes Concepts Covered in the Video
- Amazon Elastic Kubernetes Service (EKS)
- Kubernetes
- Namespaces
- DaemonSet
- StatefulSets
- Configure ServiceAccounts for Pods
- Using RBAC Authorization
- Kubernetes Token Review API and Authentication
- ConfigMaps
- Secrets
- Configure Liveness, Readiness, and Startup Probes
- Service
- Deployments
- Pods
- Persistent Volumes
- Volumes
- Nodes
SPIFFE and SPIRE Fundamentals
- SPIFFE Concepts
- SPIRE Concepts
- SPIFFE Workload API
- Working With SVIDs
- Extending SPIRE
- go-spiffe: Golang Library for SPIFFE Support
Key Concepts
- Zero Trust Architecture
- Zero Trust Security Model
- Trust Boundary
- Information Security
- Public Key Infrastructure (PKI)
- How Certificate Chains Work
- Kubernetes
- Protocol Buffers
- gRPC: A Universal RPC Framework
- Unix Domain Sockets
- Inter-Process Communication
- What is CI/CD?
Algorithms and Standards
- X.509
- X.509 SVID
- Shamir’s Secret Sharing Algorithm
- Certificate Revocation Lists (CRL)
- Can we eliminate CRLs?
Related Technologies
- How Vault Seals/Unseals Using Shamir’s Secret Sharing Algorithm
- HSM: Hardware Security Module
- AWS Cloud HSM
- Istio identity with SPIFFE and SPIRE
- OPA: Open Policy Agent
- Certificate Transparency
- AWS Instance Metadata and User Data
- Amazon EKS
- Amazon Machine Images (AMI)
- ALTS: Application Layer Transport Security
- Building Facebook’s Service Encryption
- Automated Bootstrapping of Secrets & Identity in the Cloud
- The Twelve Factor App
Key Terms
Here is an non-exhaustive list of the key terms and phrases covered in this article and video. Of course, if you check the **References and Further Reading ** section above, you will find a lot more. Yet, it’s an excellent start to get acquainted with these and do more profound research around them.
Zero Trust
A security concept centered on the idea that organizations should not automatically trust anything based on whether a service is running inside or outside a network boundary and must verify everything trying to connect to its systems before granting access.
Authentication
The process of verifying the identity of a user or a system. Answers: “What are you?”.
Authorization
The process of determining the permissions of a user or a system over a resource. Answers: “What can you do?”.
Node/Worker
A logical or physical entity that runs computational workloads.
Workload
A workload is a single piece of software deployed with a particular configuration for a single purpose that can consist of multiple running instances, all of which perform the same task.
Attestation
In the context of SPIRE, attestation is asserting specific properties of a Node or Workload.
SPIFFE ID
A string that uniquely identifies a workload, e.g. spiffe://fizzbuzz.pro/service/idm.
SVID (SPIFFE Verifiable Identity Document)
A document with which a workload proves its identity. An SVID contains a SPIFFE ID.
Trust Bootstrap
Establishing Trust in a service or system.
Trust Domain
Corresponds to the Trust Root of a system. A SPIFFE trust domain is an identity namespace that is backed by an issuing authority.
Root of Trust
A source in which another trust is built on.
Signing
The addition of a digital signature for verifying the authenticity of a message or document.
Mutual TLS (mTLS)
A cryptographic protocol that ensures that the network traffic is both secure and trusted in both directions between a client and server.
Public-key cryptography (asymmetric cryptography)
A cryptographic system that uses pairs of keys (private keys and public keys). One key encrypts data, while the other key is used to decrypt the data. For example, X.509 Digital Certificates are created using public-key cryptography.
PKI (Public Key Infrastructure)
A set of policies, procedures, and tools used to create, manage, and distribute digital certificates.
X.509
A widely used standard format for public-key certificates. These certificates are used in many internet protocols, including TLS/SSL.
X509-SVID
The X.509 representation of an SVID.
Kernel
The central part of an operating system, which manages the memory, CPU, and device operations.
Hardening
The process of putting a system through a sequence of actions to increase its security posture, including patching, updating configuration, and limiting network access.
Hardware Security Module (HSM)
A dedicated cryptographic processor designed to manage and safeguard sensitive keys.
Key Management Service (KMS)
A system that manages cryptographic keys. It deals with generating, exchange, storing, and revocation of keys.
Conclusion
In this article, we’ve seen how hard it is to manage service identity across clusters at scale. We also had a demo video showing how you can install SPIRE on an AWS EKS Kubernetes cluster. In the video, we also consumed the SPIRE Agent’s Workload APIs to get SVIDs in no time.
When it comes to identity federation, SPIFFE and its reference implementation SPIRE solve many cross-cutting concerns. Some of these common problems are secret management, secret creation, secret sharing, and secret invalidation. With SPIRE, you don’t need to trust the network or create firewall rules and access control lists.
Using the foundation that we created in this article, we’ll create a service to service mTLS communication channel in the follow-up articles.
Until then… May the source be with you 🦄.
Section Contents
▶ Setting Up SPIRE on EKS in Less Than Ten Minutes